This week was primarily centered on clarifying the focus of our project, as well as on the retrieval of relevant sources of data. During the first part of the week, our group searched TidyCensus, the USDA and various other internet sources for data that could potentially be useful for whichever type of tool that we and our client decide on.
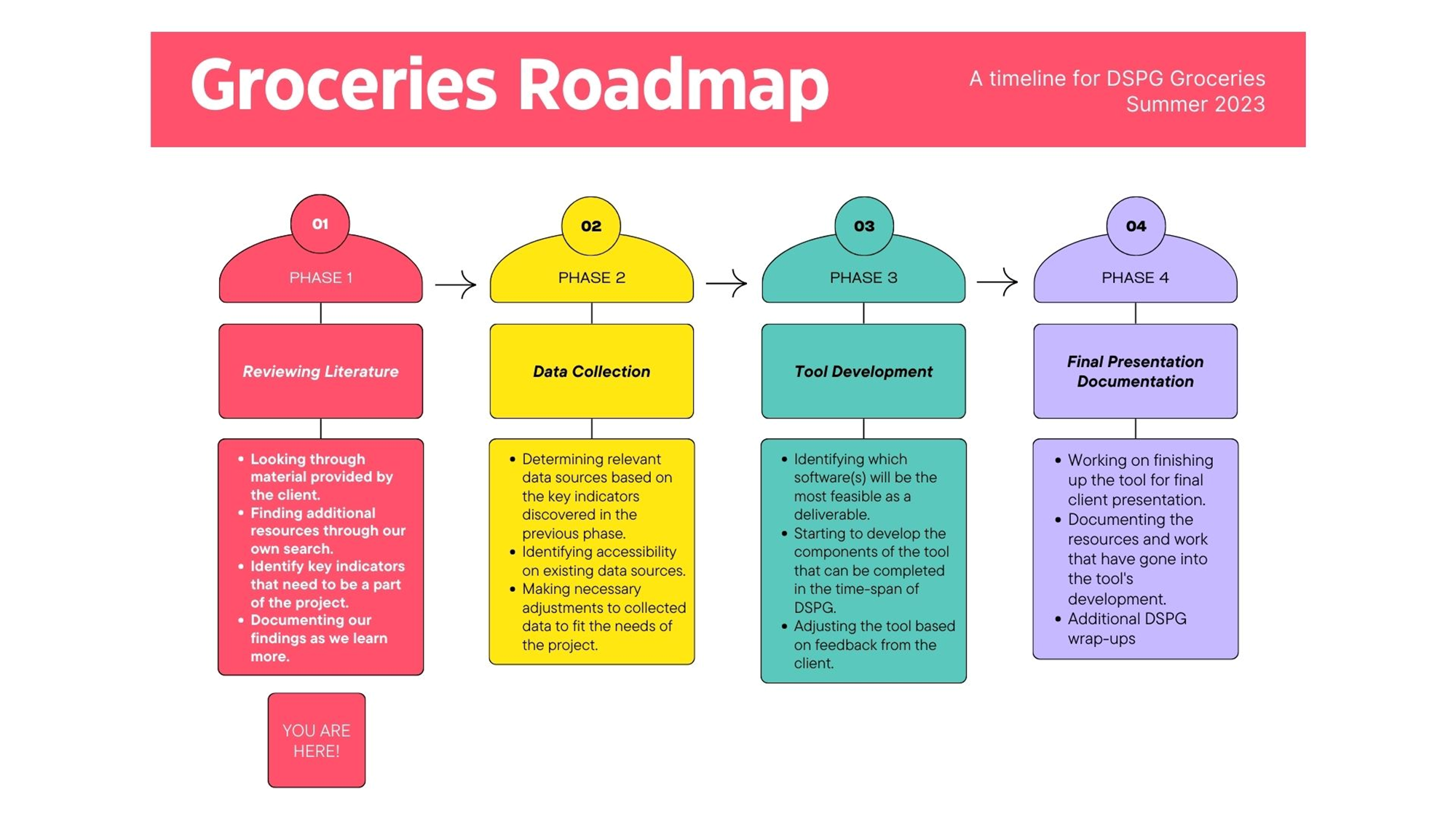
It could be said that we have started moving into the second phase of our project this week: data collection.
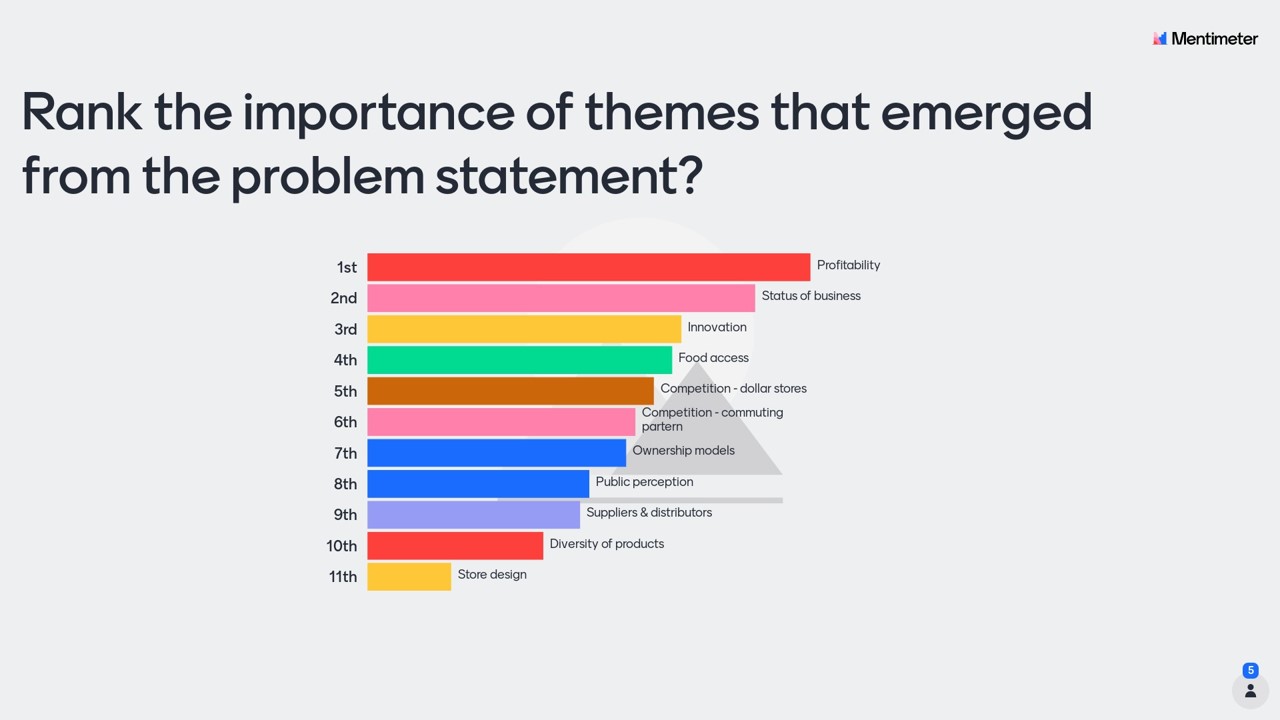
On Thursday, we met with our client and some of his associates at the the research park to discuss the direction of the project. We had them answer various questions on Mentimeter and showed them the list of datasets under consideration. They also gave us numerous suggestions about sources they were familiar with and told us that they would help grant us access to those of which were not immediately available to us.
Here are some of the Mentimeter results from our meeting:
As we are wrapping up this week, we have now shifted our focus to compiling our selected data to our repository and filtering through sources that may not be as useful as others. We are continuing to think of ways to optimize this process, as well as remaining open to other sources of data or information that we have yet to discover. Here are some of the resources under consideration:
Works in Progress
Aaron
This week has been less coding-centric than the previous week, as many of our efforts have been centered on uncovering useful sources of data. However, I have tried to work through ways to accelerate the time-consuming process of labeling and pushing CSVs of tables of ACS data.
Here is an example of such a table: “Mode of Transport to Work by County 2021”
I have also written a function that I’ve been using to speed the process up. It’s a data labeler function that takes “table”, “year” and “geography as arguments and outputs a labelled ACS5 data table by joining labels from the”load_variables()” function in TidyCensus by the common variable code on both dataframes.
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(tidycensus)library(stringr)library(readr)data_labeler_Iowa <-function(table, year, geography){ df <- tidycensus::get_acs(geography = geography,table = table,state ="IA",year = year,survey ="acs5") vars <- tidycensus::load_variables(year, "acs5") vars <- vars %>% dplyr::filter(stringr::str_detect(name, table)) vars <- vars %>% dplyr::rename(variable = name) vars <- vars %>% dplyr::select(variable, label) df2 <-merge(df,vars) df2 %>% dplyr::arrange(GEOID)}Median_Household_Income_County_2021 <-data_labeler_Iowa("B19013", 2021, "county")
Getting data from the 2017-2021 5-year ACS
head(Median_Household_Income_County_2021)
variable GEOID NAME estimate moe
1 B19013_001 19001 Adair County, Iowa 57944 4047
2 B19013_001 19003 Adams County, Iowa 57981 7853
3 B19013_001 19005 Allamakee County, Iowa 59461 2644
4 B19013_001 19007 Appanoose County, Iowa 46900 5645
5 B19013_001 19009 Audubon County, Iowa 54643 5861
6 B19013_001 19011 Benton County, Iowa 72334 3626
label
1 Estimate!!Median household income in the past 12 months (in 2021 inflation-adjusted dollars)
2 Estimate!!Median household income in the past 12 months (in 2021 inflation-adjusted dollars)
3 Estimate!!Median household income in the past 12 months (in 2021 inflation-adjusted dollars)
4 Estimate!!Median household income in the past 12 months (in 2021 inflation-adjusted dollars)
5 Estimate!!Median household income in the past 12 months (in 2021 inflation-adjusted dollars)
6 Estimate!!Median household income in the past 12 months (in 2021 inflation-adjusted dollars)
Building on this, I tried to iterate through all of these arguments by using nested for loops and writing csvs automatically. However, for a reason I don’t entirely understand, I haven’t gotten it to work the way I should. It’s possible that this has to do with the limitations of the API call and its speed within the loop.
However, even if this didn’t completely work, I learned a lot of useful information, such as the “sprintf” function that provides placeholders for strings that are named from iterating variables in loop, as well as how to call only necessary elements of a library into a function to prevent using too much memory/slowing run time.
Alex
Data Exploration
I spent a lot of time this week doing data exploration. I found the USDA food atlas data set, as well as the Economic Census data. I also explored the TinyUSDA package.
Client Meeting
This week I met with our clients, where we clarified the scope of the project, discussed the goals moving forwards, and shared our progress. I shared about the USDA food atlas and Economic Census data sets
SQL learning
This week I spent time learning PostgreSQL on DataCamp. I also did several other courses related to data visualizations and fundamental statistical skills.
Srika
Training:
Data Camp courses completed:
Introduction to statistics in R
Data visualization with R (in progress)
Created summaries of the client reports:
Understanding the market trends and margins for different departments in a rural grocery store.
Collected some ACS Data
Browsed for other possible useful sources to consider
DSPG Questions
What is the best way to scrape text off of a webpage with R?
What are some general rules/best practices for writing efficient and reliable functions?